从清华虚拟女学霸华智冰、抖音美妆达人柳夜熙,到江苏卫视2022跨年演唱会的虚拟人“邓丽君”,以及湖南卫视全新综艺《你好,星期六》启用的数字主持人“小漾”•••
从英伟达发布会上虚拟CEO黄仁勋,到美的旗下品牌华凌分别担任美的的数智体验主理人和潮流设计主理人虚拟偶像凌魂少女·凉然、凌魂少女·暖沁•••
伴随着元宇宙的兴起,虚拟数字人正越来越频繁地出现在公共视野。数字员工、虚拟偶像、虚拟代言人、虚拟主播•••数字人在社交、媒体传播、营销、传统产业等领域的价值正在逐渐显现。
制作数字化虚拟人物,有形无声,是不完善的。个性化的声音可以使形象更立体。更声入人心。但是传统人工配音,非常依赖配音演员的状态和稳定性。而且费用高效率低。不能满足高频应用的需求和发展方向。
随着AI语音技术越发成熟,通过发音定制,应用TTS语音合成技术,为数字化人物带来全新的升级,经过训练的声音让创建的虚拟人物及动画形象,通过AI语音技术自主发声。大大降低实施成本,提升工作效率。一次定制,N次应用。时刻工作状态,满足高负荷任务需求。
微软、百度、云知声等公司因为丰厚的技术积累,可以把语音识别、语义理解、语音合成、虚拟形象驱动等核心技术融入虚拟人之中,投入企业应用市场,赋能千千万万的企业用户。
Forrester的一项研究显示,84%的技术领导者认为需要将AI实施到应用中,以保持竞争优势。超过70%的人认为,AI技术已经走出实验阶段,提供了有意义的商业价值。而TTS正是AI应用中的急先峰,在各行业领域中创造更加丰富的个性化体验。
在语音领域,公众熟悉的语音识别技术(ASR),是将声音转化为文字,可类比于人类的“耳朵”。
而语音合成(TTS,Text-To-Speech),是将文字转化为声音(朗读出来),可类比于人类的“嘴巴”。
大家在Siri等各种语音助手中听到的声音,都是由TTS来生成的。
《2020年中国网络音频行业研究报告》显示,2019年中国网络音频用户规模达4.9亿,行业市场规模同比上年增长55.1%,达到了175.8亿元,预计2022年中国网络音频行业市场规模将达到543.1亿元。
iiMedia Research数据显示,超过七成受访用户对AI技术在在线音频领域的发展前景看好。得益于内容的创新和多元化的应用场景,在线音频行业的市场需求将被进一步释放。
iiMedia Research的数据显示,中国在线音频用户规模保持连续增长态势,2022年在线音频用户规模将达到6.90亿人。
在线音频行业应用TTS技术产出高质量仿真语音,快速完成文本到语音的转化过程,极大加速了企业音频内容的生产能力,扩充了内容传播的渠道。
目前,TTS技术的应用呈现出井喷的发展态势。
一是覆盖语言、语音多样化。目前,专业的语音合成技术不仅支持中文、各地方言如粤语、四川话等,而且可以支持英语、日本语等多种语音,甚至可以支持合成中英混读语音。
在语音多样化上,支持企业根据业务需求,使用语音合成标记语言(SSML)或音频内容创建工具定义词汇,并控制语音参数,如发音、音调、速率、停顿和语调。
支持多种男声、女声的选择,使得音色能够覆盖多样化的应用场景,适用于电话客服、小说朗读、消息播报等场景。
支持离线音频文件、实时音频流等合成格式。
二是部署方式多样化。专业的语音合成如微软等既支持个性化、多语种、多音色的本地化部署,满足私有化、数据隐私需求,也如微软支持云部署,在利用公有云的弹性资源,向用户应用提供更好的语音服务。
同时云服务商提供从云到边缘的任何位置都可以部署TTS应用。使用容器将逼真的语音合成构建到针对强大的云功能和边缘区域性而优化的应用中。
三是应用场景多样化。以云知声为例,其音库定制平台就在众多企业应用场景落地。如在语音导航方面、提示播报、新闻听书,人机交互、智能客服、短视频配音等提供服务。
语音导航,可以快速生成高质量的播报音频,实现在开车、走路等不方便阅读消息的情况下,音频消息的即时传达。
提示播报主要应用在高铁、广场、旅游园区、购物中心等公共场景,结合场景特性、定制适用的发音语态,进行语音播报,广播通知。
新闻听书则是将电子教材、小说等文本材料,以文本文件的形式导入离线语音合成引擎,产生完整的可重复阅读的有声教材或者有声小说,方便用户随时取用。
在客服机器人、服务机器人等场景中,则是与语音识别、自然语言处理等模块联动,打通人机交互的闭环,实现高品质的机器人发声,不仅可以满足金融、医疗、运营商等不同行业在催款、营销、回访等场景中应用,使合成声音更加真实,提升工单处理效率并降低成本。
短视频配音场景中,知识科普、教程讲解、美食教程、影视解说等各种短视频旁白配音场景,多发音人配合使用可完成剧情对话演绎。
语音合成的企业应用场景远被想象的多,而企业应用场景的开发,或许会操作一种新的商业模式。
四是覆盖行业多样化。目前,在电信、金融、传媒等众多行业,语音合成都得到应用,创造与众不同的新应用。
例如,新华社打造的A.I.虚拟主播在持续运营中,为用户每天实时播报最新的新闻动态。
广西卫视新媒体平台AI主播小晴上线“战疫情”特别报道《战疫进行时》,为公众播报最新疫情,解读疫情防控政策,普及科学防控知识,讲述“逆行者”的感人故事,助力全面打响疫情宣传攻坚战,给广西卫视新媒体矩阵500多万粉丝带来全新的用户体验。
高德邀请林志玲、郭德纲、TFBOYS、罗永浩、黄晓明、高晓松等众多流量担当来录制导航语音包。经过模型训练后,高德就推出了用户喜欢的林志玲声音导航的方式,提升了用户的体验。
其中通用TTS,在用户预期不苛刻的场景中,能满足商业化需求。但如果用户预期比较高,通用TTS会有“机器感/机械感”,不能自然地模拟人声。
个性化TTS根据数据产品特点提供不同类型的声音进行个性化定制语音库,应用在用户预期不苛刻的场景,能满足企业商业化需求。
而情感TTS更加趋于人类的真实语言,让机器被赋予情感而不只是一台冰冷的复读机。而想要让这样一台机器生动地说话,情感合成语音技术背后的数据库也将更为丰富多样。
据介绍,TTS技术正处于重大变革期,端到端(End-to-End)的TTS建模方法,加上WaveNet 的声码器思想,是未来TTS的技术发展方向
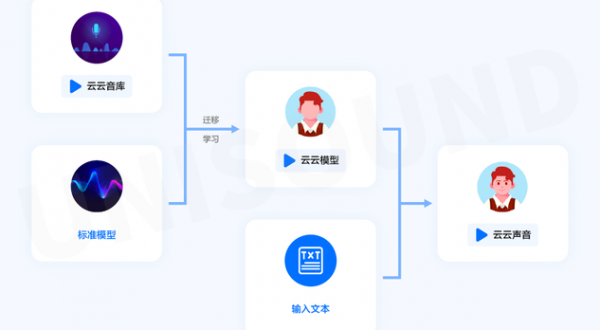
AI独角兽企业云知声AI开放平台上线的“音库定制”功能,融合了业界领先的神经网络声学模型和神经网络声码器的端到端合成技术,让合成语音增加了情感和表现力。
音库定制通过迁移学习技术,在千句级别的录音上进行深度定制音色,训练出来的音库定制效果取决于原始录音的质量,录制语音越干净、稳定和自然,合成的语音与原声的相似度越高,听感更加自然。
另外,与传统内容制作方式相比,音库定制生产效率稳定,任务进度量化评估精准,效率提升30倍以上。服务器多任务并行和可长时间运算的特性,周期效率更是可以提升百倍以上。
例如对于100万字的文档,单人录制需要11~21天,而用云知声的技术,仅需3.5小时。
定制完成后,文字即可完成音频输出。不再需要出差、背稿、录制,耗费大量时间精力,而是通过快速、简单的后台操作,实现内容的高效批量生产。
此外,“音库定制”还可以满足企业更多定制化需求,如赋予智能客服更具人情味的生命力,让智能接待更加真情实感;可以丰富企业语音助手的声音形象,拉近与用户的距离,产生更多情感互动;与有声阅读行业结合,打造专属的声音IP形象,用技术赋能有声阅读行业新生态。
AI技术的应用落地越来越多样化,通过语音合成技术,用户可以一秒变声社会名人或者其他想模仿的声音。这时,你会感到惊喜还是惊恐?
对企业来说,在不断寻求技术突破和商业价值的同时,也应该树立对技术安全的责任心。而AI公司在语音合成技术的安全合规与隐私保护方面也做出更多探索。
为了在语音合成中全面保障隐私和安全,多家语音智能厂商均提供了众多保障措施。
如微软,语音服务是微软Azure认知服务的一部分,通过 SOC、FedRAMP、PCI DSS、HIPAA、HITECH和ISO 。微软Azure确保:数据仍然是你的数据,数据处理或音频语音生成期间不会存储文本数据;可随时查看和删除自定义语音数据和合成的语音模型,你的数据在存储中时是加密的;在Azure基础结构的支持下,Speech服务提供了企业级的安全性、可用性、符合性和可管理性。
如云知声,基于客户的实际使用场景,为客户提供定制化制作流程,采用标准模型训练、最终模型训练多重非实时语音模型训,最终通过私有化部署的方式,将定制发音人部署到客户自身的服务器上,保证企业”专属IP发音人”的私密性与安全性。
元宇宙概念兴起,虚拟数字人先行。虚拟数字人正越来越频繁地出现在公共视野,成为企业服务新场景。
一方面,完善好虚拟人功能本就可以去促进用户高效内容创作、优化用户的创作体验、满足不同领域用户的需求。
另一方面,当我们未来身处元宇宙世界,在娱乐、游戏、工作场景下的视频创意需求不断得到满足,并且通过虚拟人来连接虚拟场景。
总的来看,无论虚拟人最终的发展形态如何,首要的是与当下的现实技术和商业增长合二为一,或许才是最正确的路。
将文本转换为语音,使数字化语音听起来像人类,是人工智能领域面临的巨大挑战之一。现在,TTS已经成为语音内容创作的未来。