联系我们,获取一对一客户服务
合作咨询

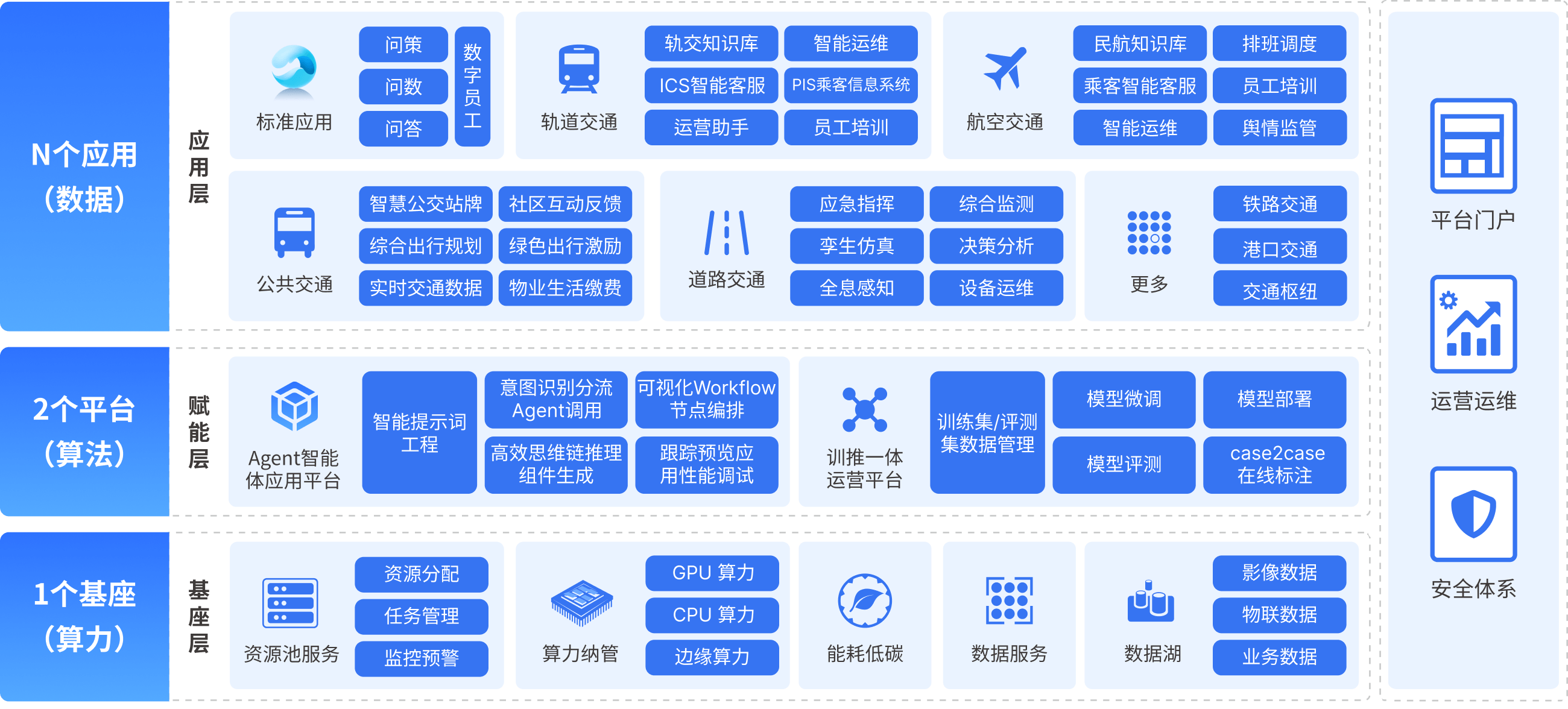
Uni-GPT一站式大模型服务应用平台”基于“1+2+N”架构体系,全面赋能全行业大模型应用场景:
N:不仅涵盖行业通用的问答、问策、问数与文本处理场景,更深入渗透到各行业的核心专业场景领域,精准匹配个性化需求。
2:两大平台提供强力支撑,深度融合数据治理、AI Agent智能体应用编排、Prompt指令工程等前沿技术,使模型构建与应用更加高效精准,结合先进的解码策略、RLHF(人类反馈强化学习)、模型微调及COT(链式思维)技术,确保模型推理的精准高效,为行业应用奠定坚实的技术基础。
1:稳固的算力基座为Uni-GPT平台的运行保驾护航,确保大模型在多元场景下的持续高效进化。



Uni-GPT一站式大模型服务应用平台”基于“1+2+N”架构体系,全面赋能全行业大模型应用场景:
N:不仅涵盖行业通用的问答、问策、问数与文本处理场景,更深入渗透到各行业的核心专业场景领域,精准匹配个性化需求。
2:两大平台提供强力支撑,深度融合数据治理、AI Agent智能体应用编排、Prompt指令工程等前沿技术,使模型构建与应用更加高效精准,结合先进的解码策略、RLHF(人类反馈强化学习)、模型微调及COT(链式思维)技术,确保模型推理的精准高效,为行业应用奠定坚实的技术基础。
1:稳固的算力基座为Uni-GPT平台的运行保驾护航,确保大模型在多元场景下的持续高效进化。
算力基座
1个基础底座,云知声Atlas AI智算平台面向 AI 模型生产的生命管理周期,平台具有300PFLOPS计算能力,提供了包括数据处理(数据集管理、智能标注和数据增强)、模型开发、模型训练和模型管理等标准化功能,方便不同知识层面的用户实现一站式AI算法构建。平台涵盖了多场景,包含语音、图像以及文本等领域的预置算法,用户能够基于自己的业务场景以及真实场景的数据,实现模型的开发,并将部署的服务开放给相应的客户进行调用。
资源池服务
算力纳管
能耗低碳
数据服务
数据湖
大模型开发与应用构建平台- 大模型数据治理模块
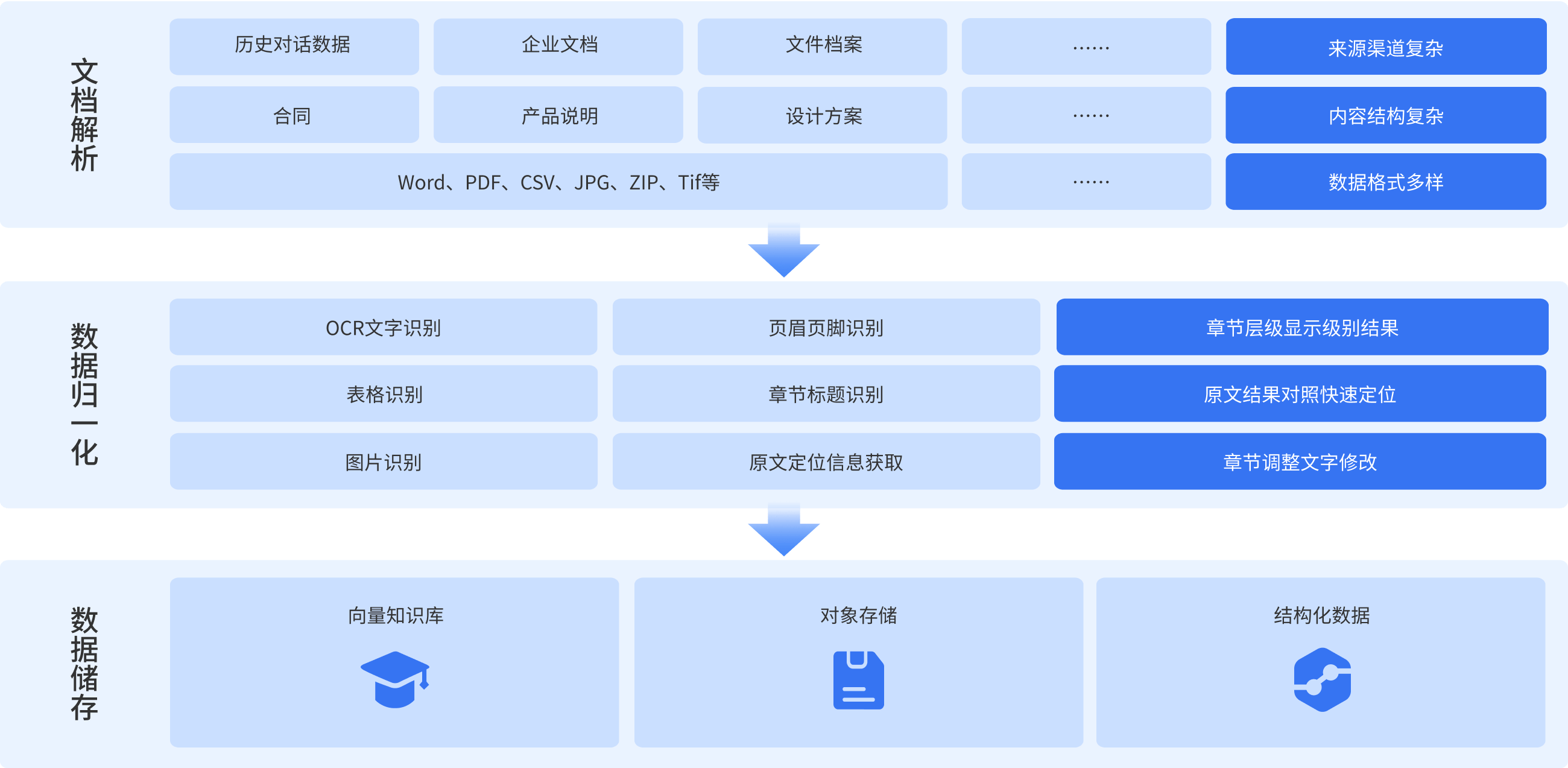
大模型数据治理专为海量知识数据管理而设计的高性能解决方案,为大模型增量化训练及微调训练提供基础输出处理支撑。支持一键解析多源异构数据集,内置AI模型实现文档内逐词句的精准检索、定位及调用,提供高度可扩展的接口,采用多元高精度OCR技术,支持自动解析原文结构及内容。
大模型开发与应用构建平台- 基于大模型增强的知识管理服务模块
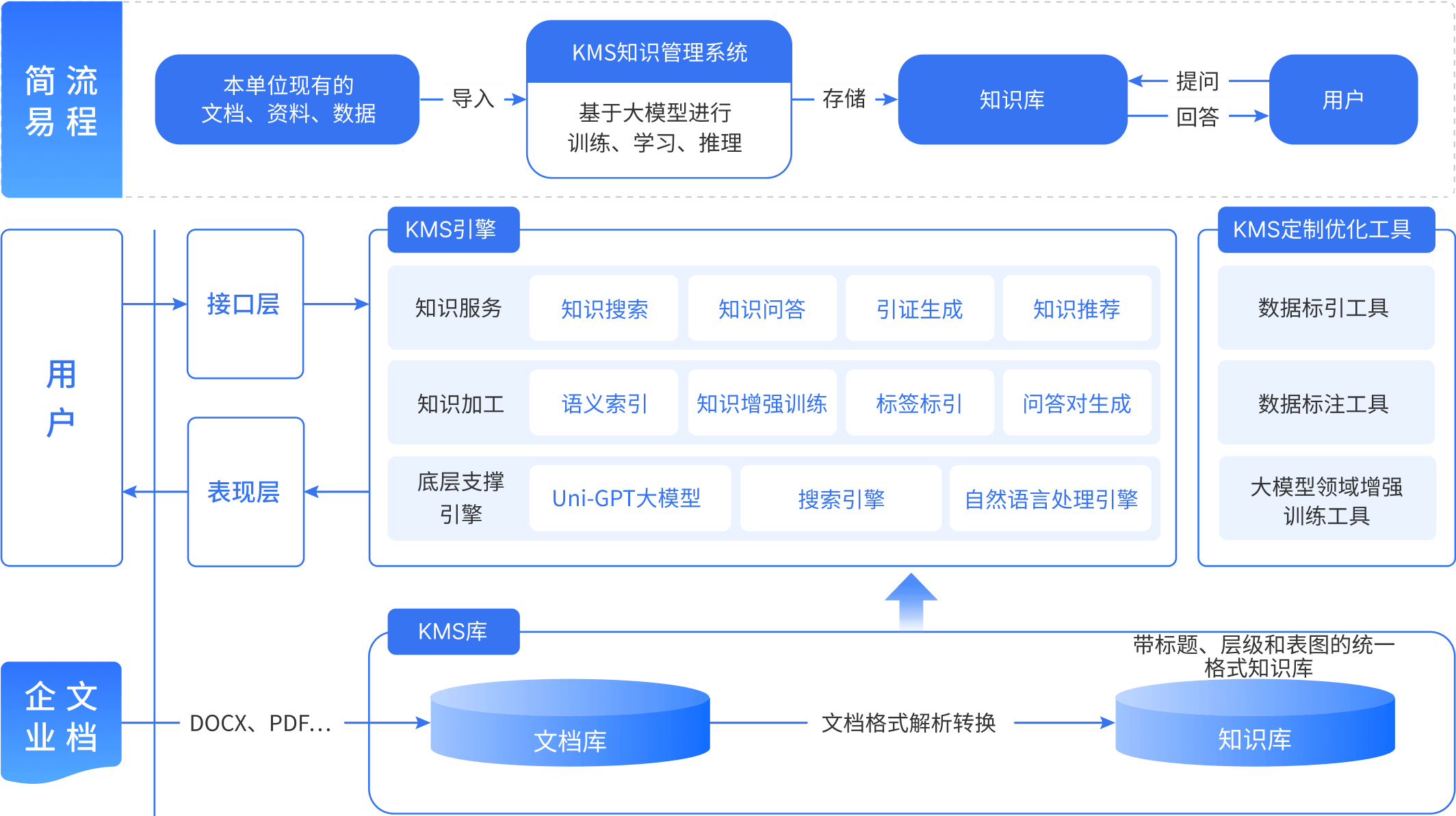
大模型深度融合知识库构建,利用深度学习和NLP增强语义理解与推理,支持多模态查询;优化策略涵盖模型压缩、数据增强、预训练及多任务学习。支持自动化知识内容生成、多模态内容融合及智能化权限管理与推荐。通过模型优化策略如压缩、预训练和多任务学习,提高效率与泛化能力,适用于多终端应用。
大模型开发与应用构建平台- 大模型Agent应用编排模块
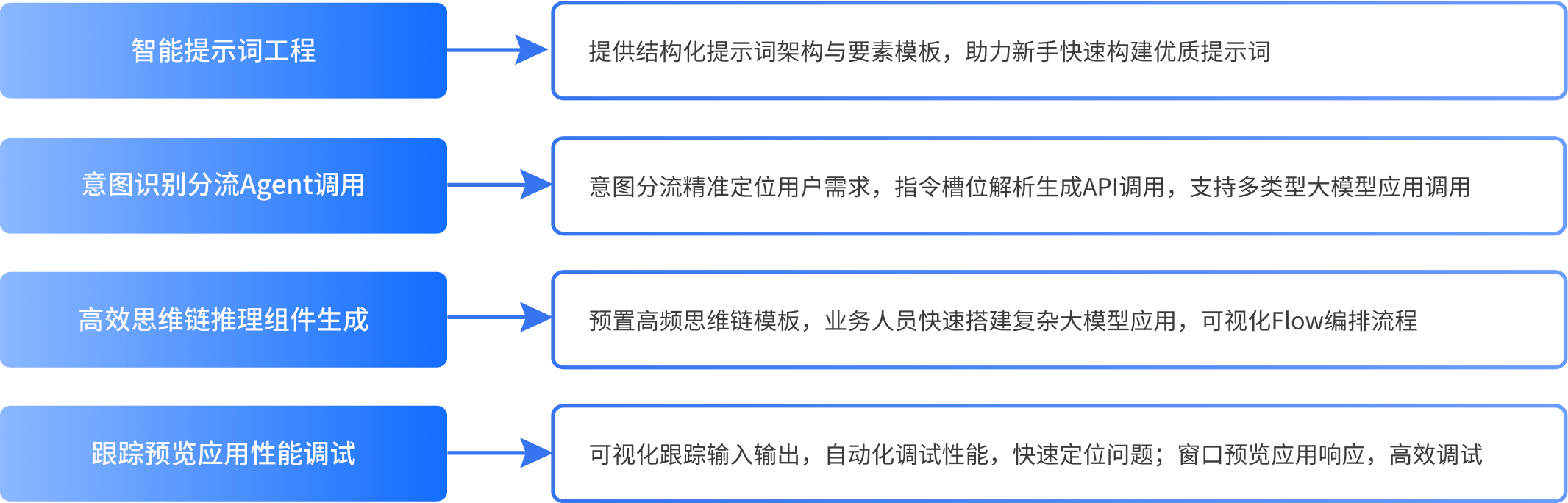
运用灵活配置与组件化策略,实现大模型RAG及Agent应用的高效搭建、测试与优化,全面满足行业业务需求。通过智能提示词工程与意图识别分流Agent,确保高质量提示词构建与用户意图精准识别。高效的思维链推理组件配合可视化的Flow节点编排,简化复杂应用搭建过程。强大的调试工具支持性能监控与实时预览,显著提升应用开发效率与质量。
大模型微调训练推理时空计算平台
创新融合用户历史数据与私有知识库,一键生成媲美专家编写的高质量、领域专属且可溯源的微调训练数据集。通过定义大模型微调数据标准,提供从模型微调到应用部署的一站式服务。内置高效智能审核机制与自研问答数据生成模型,批量产出超越行业标杆的行业领域问答数据。依托自动化QA评估体系,显著提高审核效率,并支持训练效果的可视化评估与多模型性能对比,助力迅速锁定最优模型。
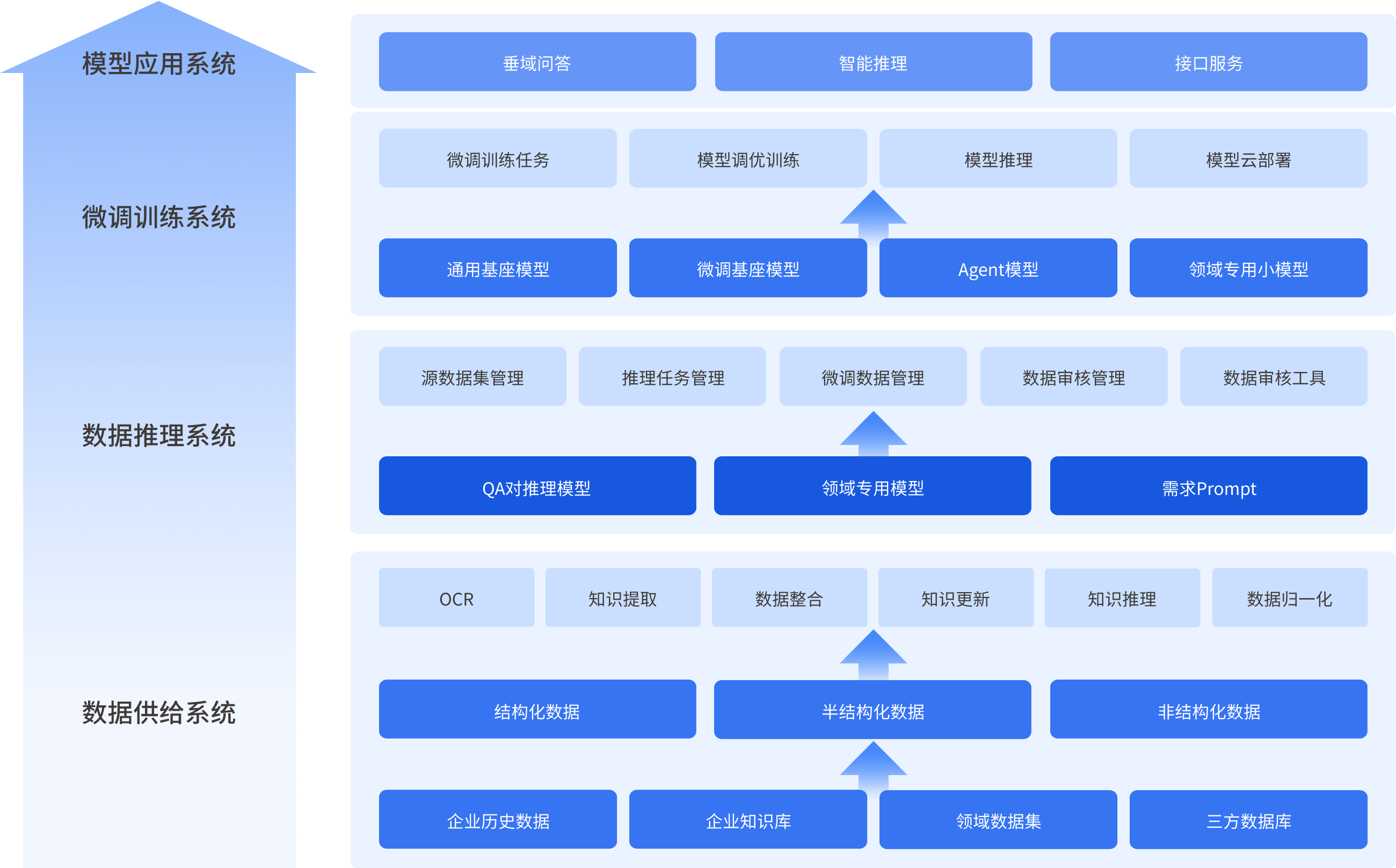
构建大模型训练评测推理与时空计算双核心引擎,支持用户自定义算法、数据与微调模式等定制各类模型,并提供开发运营全方位支持,实现模型全生命周期管理,模型集市提供垂类大模型与领域小模型,构建智慧赋能生态系统。

通过深度学习和大规模语料库的训练,大模型智能问答系统融合了RAG(检索增强生成)与COT(链式思维)技术,能够精准理解并高效回答用户提出的自然语言问题。该系统广泛应用于智能客服、高效办公助手及个性化知识培训等领域,显著提升了信息检索的准确性和速度,同时支持多语言并具备语境分析能力,为用户提供个性化的智能信息服务。

依托大模型构建全面的企业知识库,专注于企业规章制度、政策文件、工作流程及项目管理等内外部资料的精准智能问策服务。系统支持多轮对话交互,实现信息溯源与深度学习,功能覆盖知识问答、垂直搜索及文本自动化生成,为用户提供专业、高效且个性化的知识处理与决策辅助。
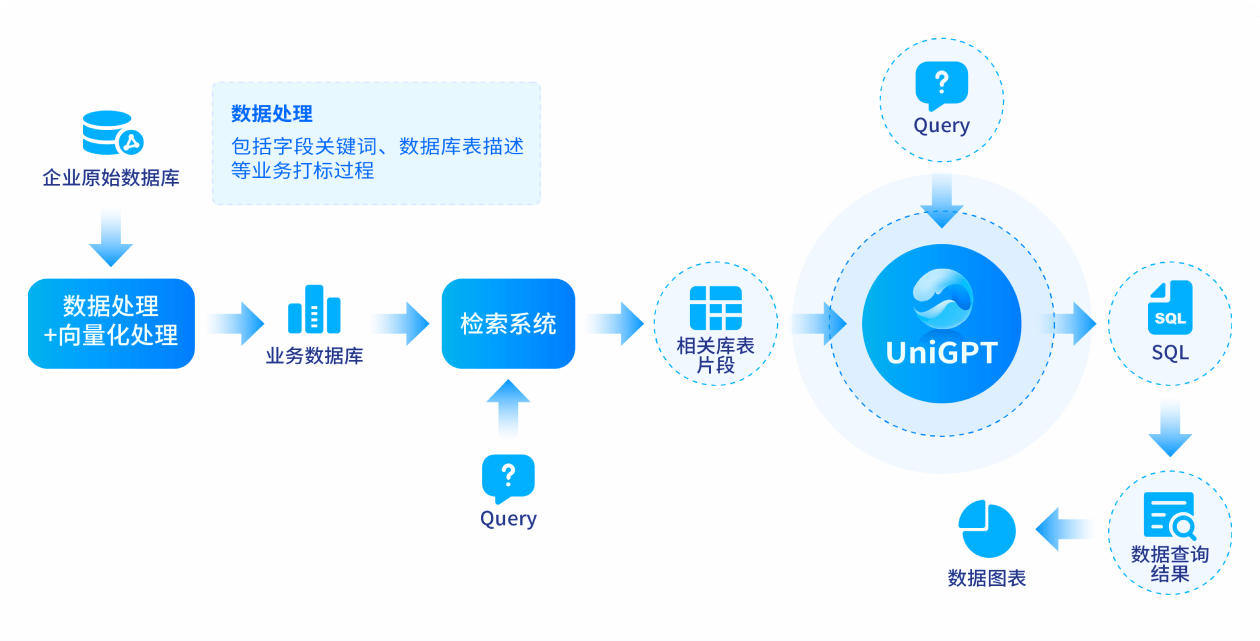
基于大模型的智能问数功能通过深度学习和自然语言处理技术,允许无技术背景的用户以自然语言形式提出数据查询需求,大模型能够智能解析用户意图,并转化为准确的SQL语句以执行数据库查询,自动生成并展示各类型的BI报表,为用户提供高效、便捷的数据分析和查询体验。

通过山海大模型,实现相关领域专业文档的自动化生成,涵盖合同、法律文件及复杂技术文档。该系统通过深度学习与自然语言处理技术,精准解析领域特定语言与规则,确保文档内容的专业性与准确性。
集成山海大模型、多模态交互、AI Agent等AI技术,可精准理解并快速响应用户的各种询问,为用户提供自然流畅的优质客户服务以及专业客服咨询能力。借助用户反馈的持续优化,无论咨询解答还是服务引导,都能提供个性化、高效的智能服务体验,让每一次交流都充满智慧与温度。

融合大模型技术、NLP和机器学习算法,结合大规模知识库(KMS),为企业提供高效、智能的运营管理解决方案。通过大模型赋能,平台实现复杂运营数据的快速分析与处理,提供精准预测与决策支持。内置KMS自动收集、整理并更新运营知识,提升工作效率,减少人为错误,助力企业智能化转型与升级。

利用预训练的大语言模型作为核心组件,结合自然语言处理技术中的Chain-of-Thought(COT)推理机制,通过构建智慧运维AI Agent智能体并与设备运维排除故障知识库集成,形成了一个能够自主学习并持续优化的智能运维系统。
